Method
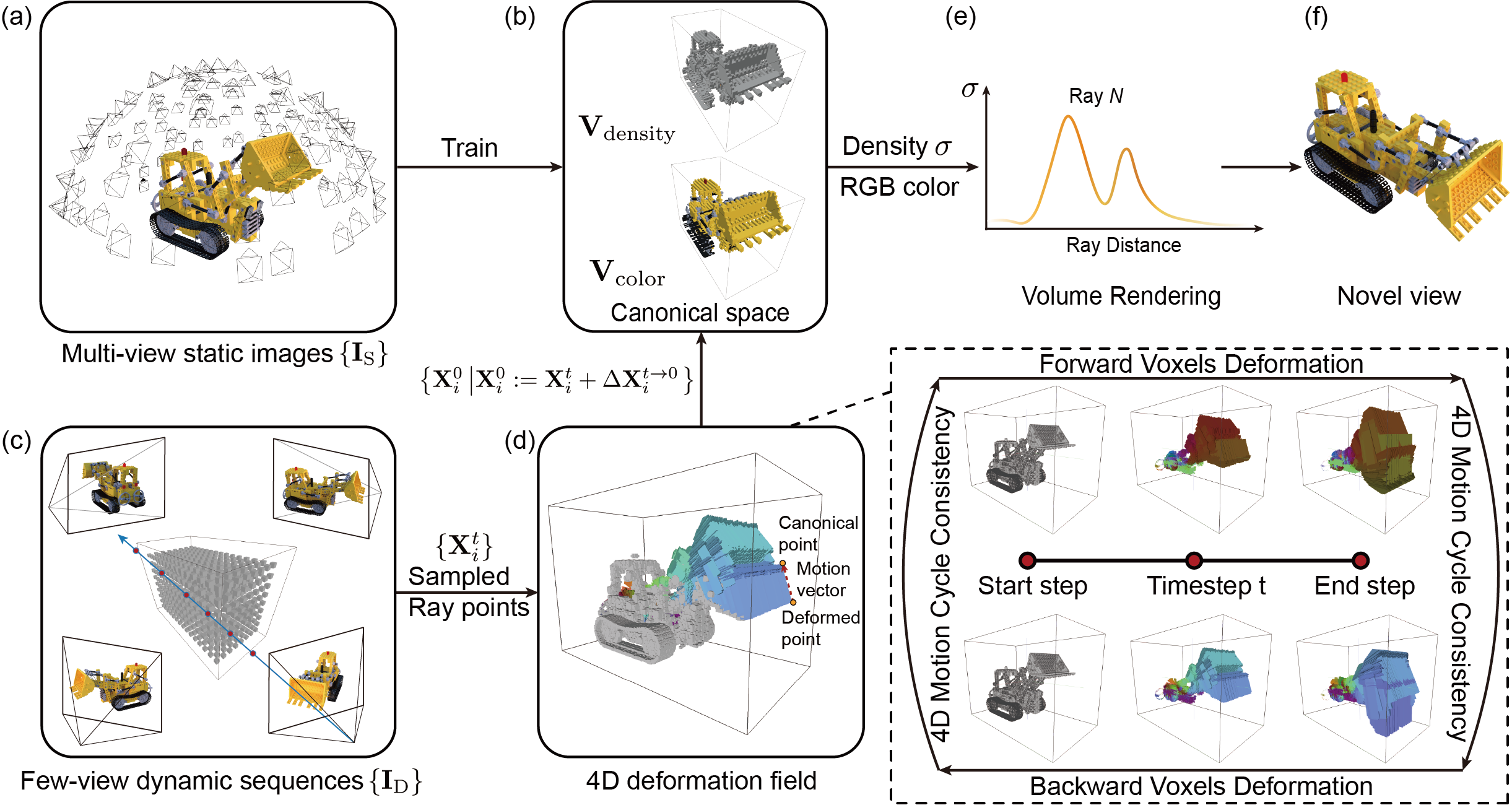
In the first stage, DeVRF learns a 3D volumetric canonical prior (b) from multi-view static images (a). In the second stage, a 4D deformation field (d) is jointly optimized from taking few-view dynamic sequences (c) and the 3D canonical prior (b). For ray points sampled from a deformed frame, their deformation to canonical space can be efficiently queried from the 4D backward deformation field (d). Therefore, the scene properties (i.e., density, color) of these deformed points can be obtained through linear interpolation in the 3D volumetric canonical space, and novel views (f) can be accordingly synthesized by volume rendering (e) using these deformed sample points.
Abstract
Modeling dynamic scenes is important for many applications such as virtual reality and telepresence. Despite achieving unprecedented fidelity for novel view synthesis in dynamic scenes, existing methods based on Neural Radiance Fields (NeRF) suffer from slow convergence (i.e., model training time measured in days).
In this paper, we present DeVRF, a novel representation to accelerate learning dynamic radiance fields. The core of DeVRF is to model both the 3D canonical space and 4D deformation field of a dynamic, non-rigid scene with explicit and discrete voxel-based representations. However, it is quite challenging to train such a representation which has a large number of model parameters, often resulting in overfitting issues. To overcome this challenge, we devise a novel static-to-dynamic learning paradigm together with a new data capture setup that is convenient to deploy in practice. This paradigm unlocks efficient learning of deformable radiance fields via utilizing the 3D volumetric canonical space learnt from multi-view static images to ease the learning of 4D voxel deformation field with only few-view dynamic sequences. To further improve the efficiency of our DeVRF and its synthesized novel view's quality, we conduct thorough explorations and identify a set of strategies.
We evaluate DeVRF on both synthetic and real-world dynamic scenes with different types of deformation. Experiments demonstrate that DeVRF achieves two orders of magnitude speedup (100x faster) with on-par high-fidelity results compared to the previous state-of-the-art approaches.